Engineering Real-Time Conversation Intelligence: A Hybrid Heuristic-Semantic Architecture for Wearable Devices
Published: January 16, 2026
Author: Neelank (Neel) Tiwari (AgendaPilot Project)
Document Type: Technical Disclosure / Defensive Publication
Abstract: This document discloses a novel system architecture for real-time conversation coaching on bandwidth-constrained wearable devices. The system solves the latency-intelligence trade-off inherent in LLM-based applications by implementing a tiered heuristic-semantic state machine. Key innovations include: (1) a multi-factor "Coverage Depth" algorithm for agenda tracking, (2) a sliding-window drift detection mechanism, (3) an "Attention Budget" protocol for notification rate-limiting on heads-up displays, (4) emergent topic discovery from off-agenda conversation, and (5) a tiered intelligence model enabling both offline heuristic and online AI-enhanced operation modes.
1. Problem Statement: The "OODA Loop" of Conversation
In high-stakes live conversations (e.g., sales demos, negotiations, medical consultations), the user's decision cycle is extremely tight—often under 2 seconds. Deploying Large Language Models (LLMs) for real-time guidance faces two fundamental constraints:
- Latency: Cloud LLM round-trips typically incur 3-5 seconds of latency, exceeding the user's cognitive decision window.
- Cognitive Load: Wearable display interfaces (smart glasses, audio-only devices) have severely limited bandwidth for presenting information without disrupting the user's primary task.
This disclosure describes a system—termed a "Conversation Hypervisor"—that addresses both constraints through a hybrid local-cloud architecture.
2. System Architecture: Tiered State-Machine Triggering
The core innovation is a Tiered Triggering System that decouples fast, local state tracking (Tier 1) from slower, intelligent generation (Tier 2).
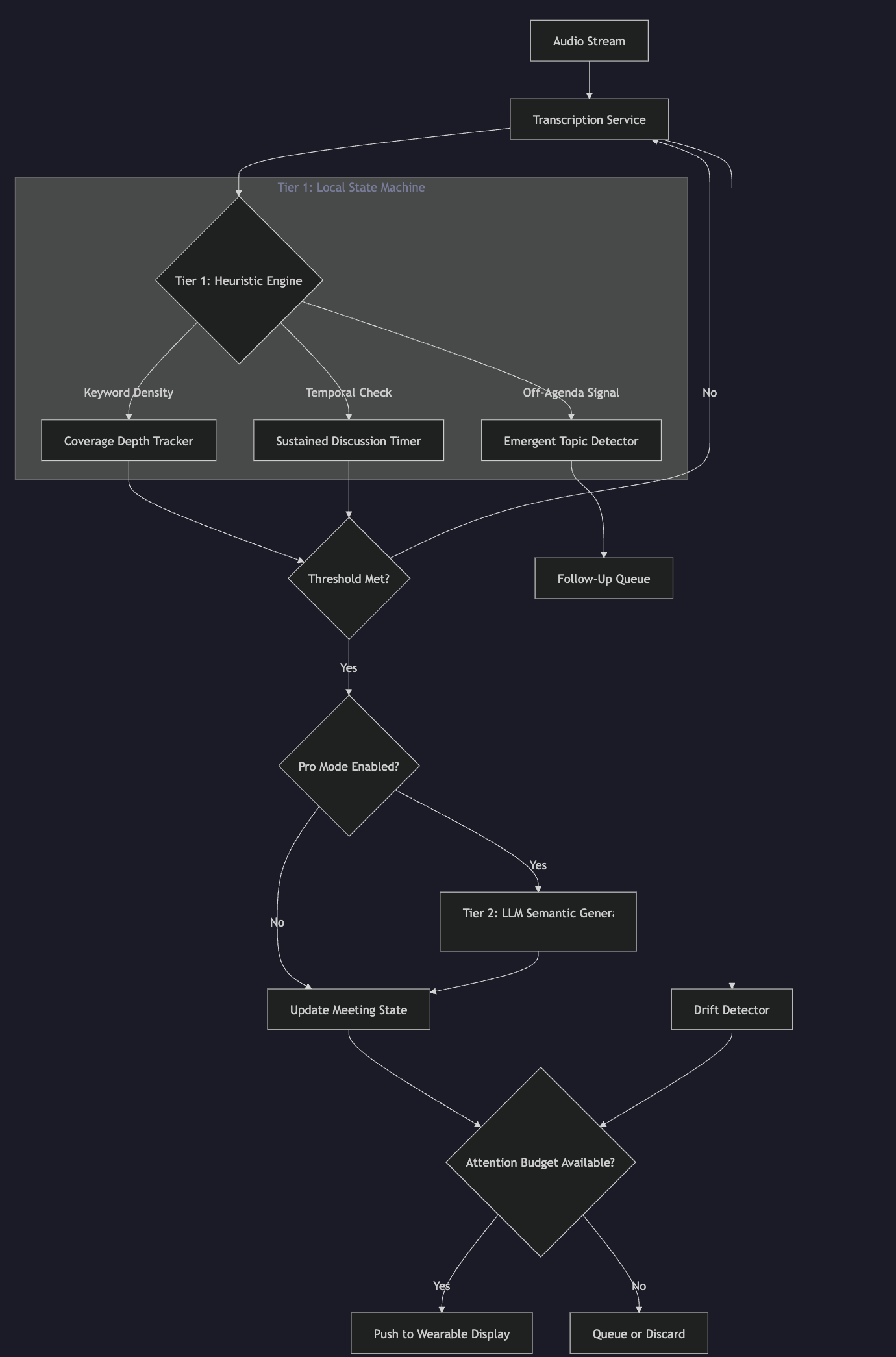
graph TD
A[Audio Stream] --> B[Transcription Service]
B --> C{Tier 1: Heuristic Engine}
subgraph Tier1 [Tier 1: Local State Machine]
C -->|Keyword Density| D[Coverage Depth Tracker]
C -->|Temporal Check| E[Sustained Discussion Timer]
C -->|Off-Agenda Signal| M[Emergent Topic Detector]
end
D --> F{Threshold Met?}
E --> F
F -->|No| B
F -->|Yes| G{Pro Mode Enabled?}
G -->|No| I[Update State with Heuristic Output]
G -->|Yes| H[Tier 2: LLM Semantic Generation]
H --> I[Update Meeting State]
I --> J{Attention Budget Available?}
J -->|Yes| K[Push to Wearable Display]
J -->|No| L[Queue or Discard]
B --> N[Drift Detector]
N --> J
M --> O[Follow-Up Queue]
2.1 Tier 1: The Heuristic Engine (Local, <100ms)
The Heuristic Engine runs entirely on the application server (or edge device) without requiring an LLM call. It maintains a Meeting State Object containing:
agenda_items[]: List of user-defined agenda items with extracted keywords.current_index: Pointer to the "active" agenda item.transcript_buffer[]: Rolling window of recent transcript segments.coverage_order[]: Sequence in which items were covered (for post-meeting analysis).
2.2 Tier 2: The Semantic Engine (Cloud, 1-3s)
The Semantic Engine (LLM) is invoked only when a Tier 1 event triggers a need for natural language generation. Use cases include:
- Generating a smooth transition phrase between agenda items.
- Generating a probing question when discussion stalls.
- Generating a redirect phrase when drift is detected.
This tiered approach reduces LLM API calls by an estimated 80-95% compared to continuous inference.
3. Core Algorithms
3.1 Keyword Extraction with Semantic Expansion
Raw agenda item text is processed to extract meaningful keywords:
FUNCTION extract_keywords(text):
text = lowercase(remove_punctuation(text))
words = split_by_whitespace(text)
keywords = []
FOR word IN words:
IF word NOT IN STOPWORDS AND length(word) > 2:
keywords.append(word)
RETURN keywords
To improve recall, keywords are semantically expanded using a predefined synonym map:
KEYWORD_EXPANSIONS = {
"budget": ["budget", "cost", "spend", "financial", "expense", "funds", "dollars", "price"],
"timeline": ["timeline", "schedule", "deadline", "date", "milestone", "duration"],
"goals": ["goals", "objective", "target", "aim", "purpose", "mission"],
...
}
FUNCTION expand_keywords(text):
base_keywords = extract_keywords(text)
expanded_set = SET(base_keywords)
FOR keyword IN base_keywords:
FOR base_word, expansions IN KEYWORD_EXPANSIONS:
IF keyword IN expansions OR base_word IN keyword:
expanded_set.add_all(expansions)
RETURN LIST(expanded_set)
3.2 The "Coverage Depth" Algorithm
A central challenge is distinguishing a passing mention of a topic from substantive coverage. A simple keyword match is insufficient.
The Coverage Depth algorithm implements a multi-factor confirmation standard:
FUNCTION check_item_coverage(transcript_window, agenda_item):
transcript_keywords = extract_keywords(transcript_window)
matched_keywords = INTERSECTION(transcript_keywords, agenda_item.keywords)
match_count = COUNT(matched_keywords)
unique_base_matches = count_unique_semantic_roots(matched_keywords)
// Depth Scoring
IF match_count >= 8 AND unique_base_matches >= 4:
RETURN depth=3 // Deep coverage
ELSE IF match_count >= 6 AND unique_base_matches >= 3:
RETURN depth=2 // Moderate coverage
ELSE IF match_count >= 3:
RETURN depth=1 // Light mention
ELSE:
RETURN depth=0 // No coverage
Coverage is confirmed only when ALL of the following conditions are met:
coverage_depth >= 2(moderate or deep).mention_count >= 3(accumulated mentions across transcript chunks).time_since_first_mention >= 5 seconds(sustained discussion gate).
This prevents false positives from fleeting references.
3.3 Drift Detection via Sliding Window Density
The system detects "drift" (conversation moving off-topic) by analyzing keyword density within a sliding window:
FUNCTION detect_drift(transcript_window, current_agenda_item):
IF current_agenda_item.covered:
RETURN false
transcript_keywords = extract_keywords(transcript_window)
matched_count = COUNT(INTERSECTION(transcript_keywords, current_agenda_item.keywords))
word_count = COUNT(split_by_whitespace(transcript_window))
// Drift Threshold: If window is large but matches are sparse
IF word_count > 100 AND matched_count < 2:
RETURN true // Drift detected
RETURN false
3.4 Emergent Topic Discovery
Valuable discussion often occurs outside the predefined agenda. The system tracks emergent topics by identifying significant words that do not belong to any agenda item:
FUNCTION detect_emergent_topics(transcript_window, all_agenda_keywords):
transcript_keywords = extract_keywords(transcript_window)
off_agenda_keywords = transcript_keywords - all_agenda_keywords - STOPWORDS
// Filter for significance (length > 4 characters)
significant_words = [w FOR w IN off_agenda_keywords IF length(w) > 4]
FOR word IN significant_words[:3]: // Limit to top 3
IF word NOT IN emergent_topics_list:
emergent_topics_list.append(word)
These emergent topics are surfaced in the post-meeting summary as potential follow-up items.
4. The "Attention Budget" Protocol
Wearable displays (e.g., smart glasses with single-line text overlays, or audio-only devices) cannot display continuous streams of information. The Attention Budget Protocol implements strict rate-limiting:
4.1 Priority Queue
Notifications are classified into priority tiers:
| Priority | Type | Example | Cooldown |
|---|---|---|---|
| P0 | Critical Success | "✓ Budget covered → Timeline" | 0s |
| P1 | Warning | "⚠️ Drifting from: Goals" | 120s |
| P2 | Suggestion | "💡 Try: What's the deadline?" | 120s |
4.2 Rate Limiting Logic
GLOBAL last_notification_time = 0
GLOBAL RATE_LIMIT_SECONDS = 30
FUNCTION can_send_notification():
IF current_time() - last_notification_time >= RATE_LIMIT_SECONDS:
RETURN true
RETURN false
FUNCTION send_notification(message, priority):
IF priority == P0 OR can_send_notification():
push_to_wearable(message)
last_notification_time = current_time()
P0 events always send immediately. P1/P2 events respect the cooldown to avoid overwhelming the user.
5. Constrained Display Interface: Wearable Integration
The system is designed for integration with bandwidth-constrained wearable devices:
5.1 Omi AI Wearable Integration
- Input: The Omi device streams audio to the Omi Cloud, which performs transcription and sends real-time transcript webhooks to the Conversation Hypervisor.
- Output: The Hypervisor sends coaching notifications back via the Omi Notification API, which pushes them to the user's smartphone companion app.
5.2 Smart Glasses Integration (e.g., Even Realities G1)
- Display Constraint: Single line of text, approximately 30-50 characters.
- Protocol: Bluetooth Low Energy (BLE) connection from the Hypervisor (or mobile app) to the glasses.
- Implication: All notification messages are truncated to a strict character limit (e.g., 80 characters maximum) before transmission.
FUNCTION truncate_message(message, max_length=80):
IF length(message) <= max_length:
RETURN message
RETURN message[:max_length-3] + "..."
6. Tiered Intelligence Model: Free vs. Pro Mode
The system supports two operational modes to balance cost and capability:
| Feature | Free Mode (Heuristic Only) | Pro Mode (Heuristic + LLM) |
|---|---|---|
| Coverage Detection | ✓ Keyword + Temporal | ✓ Keyword + Temporal |
| Drift Detection | ✓ Sliding Window | ✓ Sliding Window |
| Transition Messages | Static templates | AI-generated contextual phrases |
| Probing Questions | Static bank of questions | AI-generated based on transcript |
| Drift Redirects | Static "Return to: {topic}" | AI-generated natural redirects |
| Post-Meeting Summary | Checklist of covered/uncovered | AI-generated coaching narrative |
Pro Mode Trigger Logic:
FUNCTION generate_transition(current_item, next_item, transcript):
IF pro_mode_enabled AND llm_client.is_configured():
ai_message = llm_client.generate_transition(current_item, next_item, transcript)
IF ai_message:
RETURN ai_message
// Fallback to static template
RETURN random_choice(TRANSITION_TEMPLATES).format(item=next_item)
This allows the system to function fully offline or in cost-sensitive deployments while offering enhanced capabilities for users who opt into the AI-enhanced tier.
7. Post-Meeting Summary Generation
At the conclusion of a meeting, the system generates a structured summary:
- Items Covered: List with time spent on each.
- Items Skipped/Uncovered: Flagged for follow-up.
- Emergent Topics: Off-agenda themes detected.
- Flow Quality Metrics: Items rushed (<30s), items that ran long (>3min).
- Actionable Suggestions: (Pro Mode) AI-generated coaching tips.
8. Conclusion
This disclosure describes a complete system for real-time conversation coaching that addresses the fundamental tension between LLM intelligence and real-time latency requirements. By implementing a tiered heuristic-semantic architecture with strict attention budgeting, the system enables effective guidance delivery on bandwidth-constrained wearable devices.
The key novel contributions are:
- Hybrid Heuristic-Semantic Triggering: Local state machines for speed; LLMs only for generation.
- Multi-Factor Coverage Depth: Preventing false positives via keyword density + temporal gates.
- Sliding Window Drift Detection: Mathematical definition of "off-topic" conversation.
- Emergent Topic Discovery: Capturing value from unplanned discussion.
- Attention Budget Protocol: Priority-based rate limiting for cognitive ergonomics.
- Tiered Intelligence Model: Supporting both offline and AI-enhanced operation.
End of Technical Disclosure.




